一、目的
商高学院项目,藏经阁板块,需要采集网整理络内容,写此文档。
目前网络上有大量的书籍内容,是pdf,doc的,次方法可以转换部分doc。
二、wps另存为英文文件名
wps 转换的时候,注意,存储文件名为 英文文件名,以防后续处理会出现问题
三、使用html2text 工具去除冗余
I. 环境准备
( 1 ) python3
安装记得勾选 python3加入环境变量
( 2 ) html2text
项目地址:https://github.com/aaronsw/html2text
下载zip包后,解压到如下目录
添加到环境变量
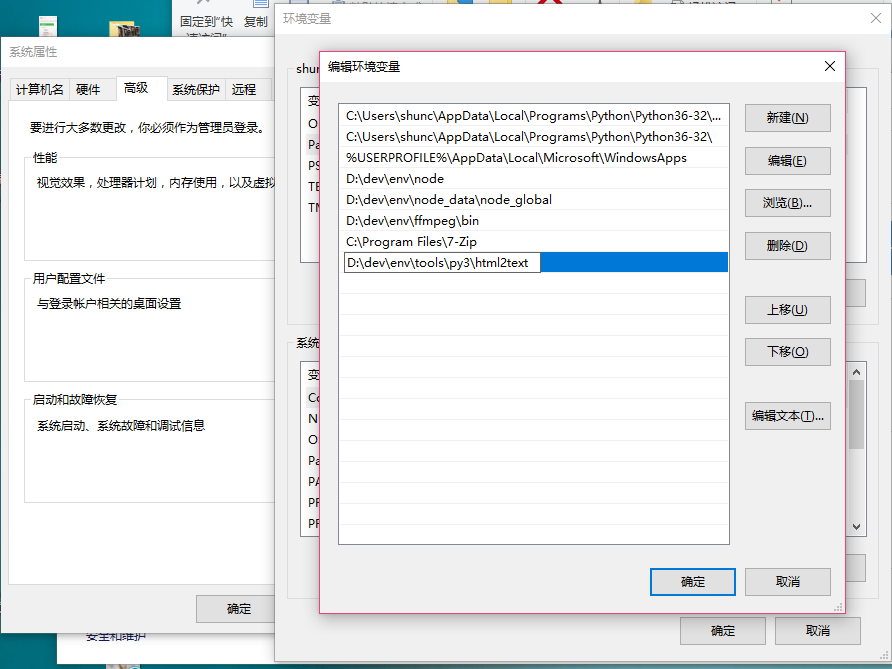
测试:html2text.py –help
II. 使用
- article.doc
- article.html
- article-body.html1html2text article-body.txt > article.md